First Relational Steps with SurrealDB
Are you the relational type when it comes to databases? Do you like Postgres, have heard of SurrealDB, and want to know if it's worth a shot? This post is for you :)
What is SurrealDB?
SurrealDB is a multi-modal database. You can store relational data, graphs, documents, and time series in it. It supports full-text search, vector search, has its own SQL-like query language, and lets you store and execute ML models. You can have fine-grained access control (down to fields, aka columns), which leads to their claim of being a backend as a service (think Firebase).
That's quite a lot cover. I’ll focus on relational data storage, consistency, querying, performance, and DX. Here we go.
Data Consistency
Strict Mode
You can start SurrealDB either with or without the strict flag. Without, you can create records (in Postgres, these would be rows) without defining their schema. That might be cool for prototyping, but it's not my cup of tea. Note that strict mode is either on or off for the entire database instance.
Here I create a dog record without defining a schema for it:
-- insert record
create dog content {
name: "cookie",
good_dog: true
};
With strict mode, you need to define what records exist (e.g. dog), but not necessarily how they look:
-- define table
define table dog schemaless;
-- insert record
create dog content {
name: "cookie",
good_dog: true
};
Schemafull & Schemaless
We defined a schemaless table for dog, and aside from actually putting records in that specific table, they can have pretty much any shape or form we want.
create dog content {
title: "sir doggo",
age_years: 3
};
By the way, all records have IDs, which are generated automatically if not explicitly specified.
We can define fields for schemaless tables. Inserting with extra fields is acceptable (and they become part of the stored record), but inserting with missing fields returns an error:
define table dog schemaless;
define field name on dog type string;
define field age_years on dog type int assert $value >= 0;
-- this insert works!
create dog content {
name: "cookie",
age_years: 2,
extra_field: "good dog"
};
-- doesn't work, because "age_years" is missing
create dog content {
name: "cookie"
};
Now we're done prototyping and know how the schema should look. We discard the old table and define it again, this time as schemafull. Trying to insert records with missing or extra fields will return an error for schemafull tables.
remove table dog;
define table dog schemafull;
define field name on dog type string;
define field age_years on dog type int assert $value >= 0;
create dog content {
name: "cookie",
age_years: 2
}
Altering the Schema
One thing I really don't like about SurrealDB: If we change, say, a field's type from int to string, I would expect all records in that table to conform to the new schema. However, they don't.
Here, I use the overwrite keyword (there is an alter keyword, but it works for tables only, at least for now) to change the field type of zip_code from int to string. However, existing records still have the old type for that field. You must manually update the records to fit the new schema, even in strict mode for schemafull tables 👎
-- define table
define table address schemafull;
define field street on table address type string;
define field zip_code on table address type int;
-- insert record
create address content {
street: "Second Avenue 2",
zip_code: 1234
};
-- change field type
define field overwrite zip_code on table address type string;
-- add field
define field test on table address type string;
-- remove field
remove field street on table address;
-- query records
select * from address;
Querying the addresses with select * from address; returns:
[
{
id: address:o5fabxa3eir08n731b5o,
street: 'Second Avenue 2',
zip_code: 1234
}
]
Nothing changed. Both street and zip_code (as string) are still there and the new field test is missing as well.
Altering the schema doesn't alter old data. New records will have the new schema, though.
This is especially dangerous, I think, when you've just added a non-optional field to a table that your backend code relies on to be neither null nor undefined. Older records won't have that field until you write a query to update them. That was a footgun, at least for me.
Let's transition to something more harmonious: Relations!
Record Links
There are two main ways to create relations between records. Let's explore the simplest one: Record Links. First, we need another table: human. Then we define a field of type record<dog>. I find that pretty neat.
define table human schemafull;
define field name on human type string;
define field loves on human type record<dog>;
But there is no guarantee that the dog referenced in the human table actually exists. Hm...
Relations
We could create custom events that fire on create/update/delete, but who wants that? Another way to relate two records is through a Relation. Relations are basically tables, but with two default fields: in and out, both holding a record ID. You can add more fields to describe the relation.
-- create records for human and dog
create human:human_1 content { name: "alex", loves: dog:dog_1 };
create dog:dog_1 content { name: "cookie", age_years: 2 };
-- define relation between human and dog
define table cares_for type relation in human out dog enforced;
define field since on cares_for type datetime;
-- create relation
relate human:human_1 -> cares_for -> dog:dog_1 content { since: time::now()}
Relations also won't guarantee that their related records exist—not by default. The enforced keyword used in the relation's definition will prevent the insertion of relations with missing records in referenced tables. If a referenced record is deleted, the relation will be deleted as well.
You would need to build custom events to achieve the "on delete cascade" feature that Postgres offers. However, a PR to go in that direction was opened less than a week ago. Fingers crossed 🤞
Data Storage
SurrealDB stores data in key-value stores. This is very important to know, I think. You can choose between RocksDB, FoundationDB, IndexedDB, SurrealKV, TiKV, or an in-memory KV. SurrealKV is still in beta, though.
TiKV, for instance, is horizontally scalable while being ACID compliant.
Record IDs follow the format table_name:id. Record IDs are used to retrieve records from KV stores quickly. SurrealDB strongly encourages you to use these record IDs for filtering whenever possible because they are indexed by default. And you really better do that, or else...
Performance
Performance can be a problem. As far as I know, SurrealDB hasn't published any benchmarks, which is sus. So I measured some things myself.
Test: Query Table with 1 Mio. Records
I populated a user table with one million rows in both SurrealDB and Postgres for some query benchmarks. I'm using SurrealDB 2.1.2 with the in-memory KV store and Postgres 17.0, both running in Docker on an M1 Mac.
SurrealDB
-- define table
define table user schemafull;
define field id on table user type string;
define field username on table user type string;
define field email on table user type string;
define field password_hash on table user type string;
define field coins on table user type int;
-- populate table (took 65 s)
FOR $i IN 1..=1000000 {
create user content {
username: string::concat('username' + return <string> $i),
email: string::concat('email' + return <string> $i),
password_hash: string::concat('id' + return <string> $i),
coins: rand::int(0, 1000000)
};
}
Postgres
-- define table
create table "user" (
id text primary key,
username text not null check (length(username) > 0) unique,
email text not null,
password_hash text not null,
coins int not null
);
-- populate table (took 10 s)
DO $$
DECLARE
id text;
username TEXT;
email TEXT;
password_hash TEXT;
coins INT;
BEGIN
FOR i IN 1..1000000 LOOP
id := 'id' || i;
username := 'user' || i;
email := 'user' || i || '@example.com';
password_hash := 'hash' || i;
coins := (RANDOM() * 1000 + 1)::INT;
INSERT INTO "user" (id, username, email, password_hash, coins)
VALUES (id, username, email, password_hash, coins);
END LOOP;
END $$;
I then queried both databases for:
- Number of users
- Ten users with the most coins
- Sum of all coins of all users
My measurements aren't very scientific or exact, but they're still worth a look, I think. Keep in mind: Postgres has been around for a long time. SurrealDB is relatively young, and performance optimizations could be coming. They could be huge. Or not. I don't know.
Results SurrealDb
-- count all users ≈ 6 s
select count() from user group all;
-- get ten users with most coins ≈ 8 s
select * from user order by coins desc limit 10;
-- sum of all coins from all users ≈ 8 s
select math::sum(coins) from user group all;
Results Postgres
-- count all users ≈ 38 ms
select count(*) from "user";
-- get ten users with most coins ≈ 30 ms
select * from "user" order by coins desc limit 10;
-- sum of all coins from all users ≈ 25 ms
select sum(coins) from "user";
As you can see, Postgres is orders of magnitude faster than SurrealDB for these queries.
Indexes to the Rescue?
What about indexes? Can't they help with, say, ordering by coin amount? Creating an index for the coins field and re-running the query for the ten richest users reduced the time for that query by ... nothing?. It still takes about 8 seconds in SurrealDB. I'm not sure if I did something wrong, but I expected a little speedup:
-- define index ≈ 26 s
define index coins_index on table user columns coins;
-- get ten users with most coins ≈ 8 s
select * from user order by coins desc limit 10;
Adding an index for email and querying for two users with an email containing email9999 drops the time from approximately 8 seconds to about 50 milliseconds when using an index. So indexes can help you:
-- select without index ≈ 8 s
select email
from user
where email contains "email9999"
order by email desc
limit 2;
-- define index ≈ 25 s
define index email on table user columns email;
-- select with index ≈ 50 ms
select email
from user
where email contains "email9999"
order by email desc
limit 2;
Local vs. Cloud
And for good measure, I did the exact same measurements on a DB instance in SurrealDB's cloud. Just in case my way of running the DB locally was the bottleneck. Here is a summary of all results
Postgres local
| Query | Time |
|---|---|
| populate table | 10 s |
| count all users | 38 ms |
| get ten users with most coins | 30 ms |
| sum of all coins from all users | 25 ms |
SurrealDB local
| Query | Time |
|---|---|
| populate table | 65 s |
| count all users | 6 s |
| get ten users with most coins | 8 s |
| sum of all coins from all users | 8 s |
SurrealDB cloud (free tier)
Populating the table worked, but i got The engine reported the connection to SurrealDB has dropped for the rest of the queries. Every time. It might be that the free tier is too slow for these queries.
| Query | Time |
|---|---|
| populate table | 339 s |
| count all users | ?? s |
| get ten users with most coins | ?? s |
| sum of all coins from all users | ?? s |
SurrealDB cloud (paid "large" instance)
This instance has 2 vCPUs, 8 GB RAM, and 64 GB storage and costs $0.301/hour or about $215/month.
| Query | Time |
|---|---|
| populate table | 48 s |
| count all users | 3 s |
| get ten users with most coins | 6 s |
| sum of all coins from all users | 4 s |
Bugs
If you want to use SurrealDB in production, I recommend first skimming through their GitHub issues labeled with "bug". That might sober you up before jumping on the hype train too quickly.
This one kept me busy for a while: SELECT * FROM users WHERE email CONTAINS "@example.com" returned no results if email had an index.
Another, similar issue I ran into also altered a SELECT query’s result if an index was present versus not. But it got resolved a few days after I published this post. Thanks to @mithridates on Bluesky for letting me know :)
I have little doubt that the SurrealDB team will fix these bugs and others like them. But for now, they are there and you should be aware of them.
Developer Experience
As demonstrated in this post, Hugo, my SSG of choice, has syntax highlighting for SQL but not for SurrealQL. At least for now.
But there are syntax highlighting extensions for VS Code, Vim and Zed, the editors I'm working with.
SDKs
SurrealDB has quite a few SDKs for different languages. I've worked with the ones in Rust and Typescript. The one in Rust is fine, as is the one in Typescript.
But using the latter revealed a rather unpleasant side effect of record IDs in SurrealDB: As mentioned, they are composed of the table's name and the record's ID (table_name:record_id), e.g. user:1234. When querying the DB, it returns an object where the IDs are of class RecordID. Additionally, that class cannot be serialized to JSON. So you have to use the utility method jsonify() on on objects retrieved from the DB before you can, for example, send them as JSON to a client, who called your REST API.
The client gets user:1234 as a string and needs to work with it. Suppose it wants to generate a link to the profile page of a user. Unless you manually remove the table part from the record ID, a link would look like this: /users/user:1234/profile.
As far as I know, their SDK doesn't offer a method to convert a string back to a RecordID, which has methods for safely extracting the table and ID parts. Doing that manually might be trivial for record IDs like user:1234, but the ID part could also be an array or object.
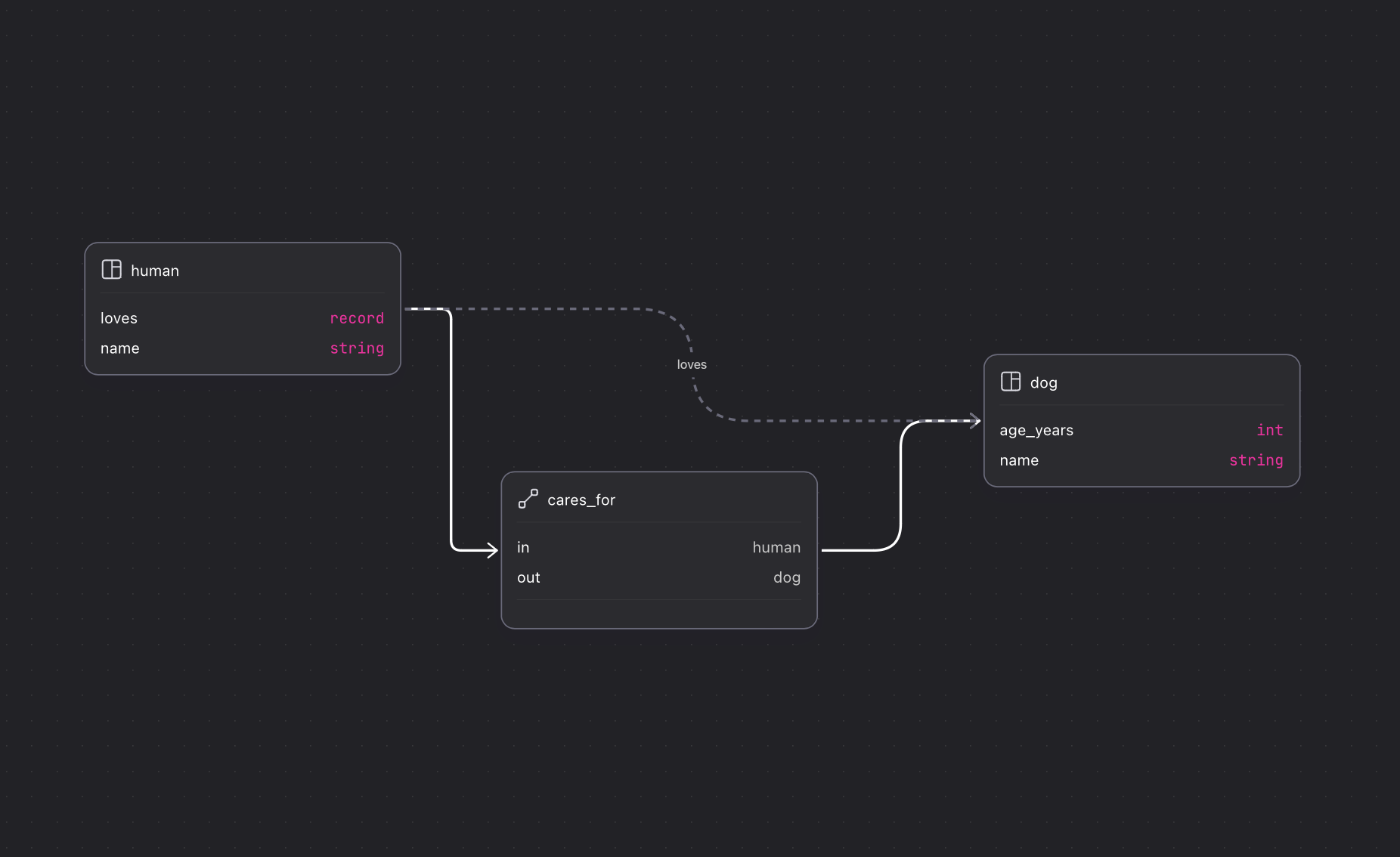
Surrealist
Surrealist is the GUI for SurrealDB, and it is neat. It lets you manage connections to many DBs, query them, visualize their content, and it even paints you a pretty view of your relational data model. Here you can see the Record Link loves and the Relation cares_for between human and dog that we created earlier:
Conclusion
I'm excited about this relatively new piece of DB technology! The feature list is genuinely impressive. Here are three more that I find particularly interesting:
- Live queries actively pushing data to the client when new records pop up
- Make HTTP calls from within the query language
- Run SurrealDB in WASM in the browser
Having one DB to store all your data (graph, relational, time series, and more) is compelling. However, I wouldn't use it in production until it gets quite a bit faster, resolves pressing index issues, and offers more convenience for data consistency, like on delete cascade, and an alter keyword that also alters data, not just the schema.
But it's fine for side projects like these I've built with it so far:
- Botto - a general-purpose chat bot for the Matrix protocol
- Recipe Robot - an AI-powered web app that extracts ingredients from recipes and matches them with actual products from a grocery store, with prices and everything
I'm working on two other projects powered by SurrealDB, and I will keep this blog post updated in case there are any more findings along the way.
Your Turn
If you want to get hands-on with SurrealDB, I recommend downloading Surrealist and setting up a local DB to play around with. You don't even have to learn the query language first to create tables, records, record links and relations. Surrealist has you covered for that.
Use this docker compose file to start a local SurrealDB instance:
version: "3.8"
services:
surreal:
image: surrealdb/surrealdb
ports:
- "8000:8000"
volumes:
- ./db_data/content:/data/
environment:
- SURREAL_NAMESPACE=default
command:
[
"start",
"--username",
"test",
"--password",
"test",
"--strict",
"file:/data/database",
]