
Playing with Postgres Transaction Isolation Levels
In this post we‘ll have a look at transaction isolation levels in Postgres. But first, let‘s have a short recap about transactions and why they‘re needed.
What is a Transaction?
A transaction combines multiple read and write steps. If a transaction is started but couldn't be completed, it will be rolled back. A rolled back transaction has no effects on the data in the database. It's an all-or-nothing operation.
Example
Let's say you have got a table for users of an online game:
| owner | balance |
|---|---|
| Lisa | 2000 |
Users can spend digital coins on stuff in the game.
You want the balance to be correct at any time. No user should be able to spend more than they have and no one should be billed twice for an item.
When Lisa logs in and buys an item for 1000 coins the sql for it could look like this:
-- check the balance to see if Lisa has enough coins
select balance from accounts where owner = 'Lisa';
-- in your business logic between the queries: check if that's enough and
-- calculate the new balance (1000)
-- update Lisa's balance
update accounts set balance = 1000 where owner = 'Lisa';
That works totally fine and Lisa's new balance is correct.
But what if Lisa is really clever and opens two sessions, one on a phone and one on her laptop?
In this case, she could click the buy-button for two items almost simultaneously:
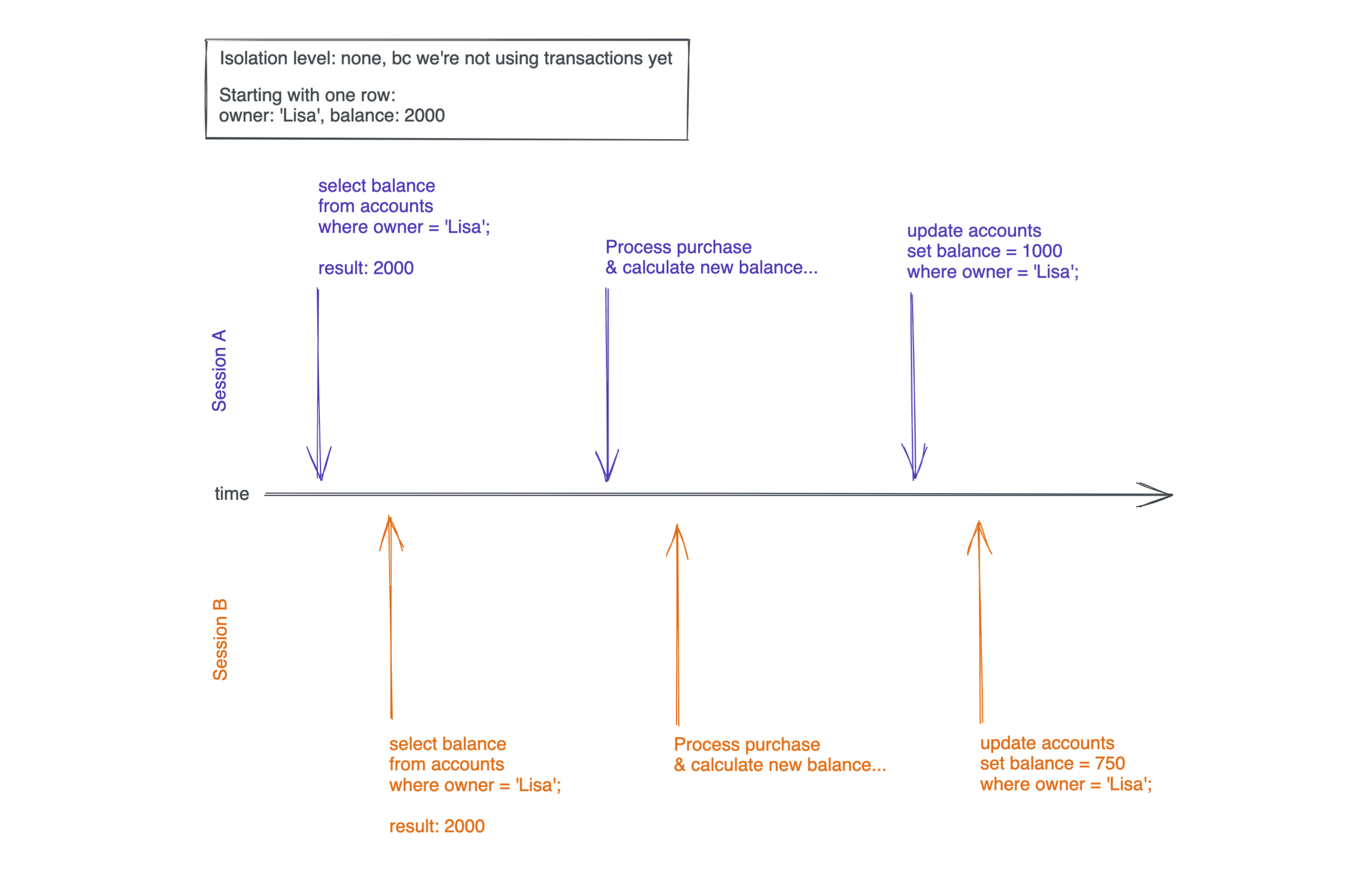
In session A Lisa buys an item for 1000 coins, so the new balance would be 1000. In Session B she purchases an item for 1250 coins, so the new balance would be 750.
The problem is that both sessions read Lisa's initial balance (2000 coins) and therefore allow the respective purchases. The latest update query sets her balance to 750 coins when she really should have -250. She effectively stole 1000 coins 🙀
Transactions can be used to avoid this total nightmare. Wrap the queries of a purchase in a transaction and Postgres ensures that the balances are correct, even when purchases happen concurrently:
-- begin transaction
begin transaction isolation level repeatable read;
-- check the balance to see if Lisa has enough coins
select balance from accounts where owner = 'Lisa';
-- in your business logic between the queries: check if that's enough and
-- calculate the new balance (1000)
-- update Lisa's balance
update accounts set balance = 1000 where owner = 'Lisa';
-- commit the transaction
commit;
Let's see what happens when we replay the scenario of two concurrent purchases. To simulate this situation we create and populate the table accounts:
create table accounts (owner text primary key, balance integer not null);
insert into accounts values ('Lisa', 2000);
From now on we need two terminals to simulate Lisa's two user sessions, terminal A and terminal B:
-- TERMINAL A
-- begin transaction
begin transaction isolation level repeatable read;
-- check the balance to see if Lisa has enough coins
select balance from accounts where owner = 'Lisa';
-- update Lisa's balance
update accounts set balance = 1000 where owner = 'Lisa';
Note that we did not commit the transaction yet, because we want to see what happens when we got two transactions running at the same time. So here comes the second one in terminal B:
-- TERMINAL B
-- begin transaction
begin transaction isolation level repeatable read;
-- check the balance to see if Lisa has enough coins
select balance from accounts where owner = 'Lisa';
-- update Lisa's balance
update accounts set balance = 750 where owner = 'Lisa';
Lisa starts with a balance of 2000 coins. In Terminal A we're processing a purchase of an item worth 1000 coins, so we're setting the new balance to 1000 coins. In terminal B we are processing a purchase worth 1250 coins and setting the balance to 750.
Without wrapping the respective queries in transactions this could actually work; Lisa would get both items and a final balance of either 1000 or 750, depending on which update query is faster.
Now we commit the transaction in terminal A:
-- TERMINAL A
-- commit the transaction
commit;
That should work just fine. But now we see this in terminal B:
-- TERMINAL B
ERROR: could not serialize access due to concurrent update
and if we try to commit the transaction in terminal B with commit; we get
-- TERMINAL B
ROLLBACK
Postgres throws an error because it wasn't safe to update the same row that was updated in the transaction of terminal A.
Only the transaction in terminal A was successful and Lisa's new balance is now 1000. Cool! Postgres saved us and Lisa's trick didn't work this time.
Three Isolation Levels of Postgres
You probably noticed that we initiated the transactions in the example with the transaction isolation level repeatable read:
-- begin transaction
begin transaction isolation level repeatable read;
Postgres has three transaction isolation levels:
read committedrepeatable readserializable
Read committed is the default option in Postgres and it would NOT throw an error in our example. That's why we choose repeatable read and that's why I think it's a good idea check what those isolation levels actually do for us.
Four Things to Worry About
There are four things to worry about in concurrent transactions:
- Dirty read
- Repeatable read
- Phantom read
- Serialization anomaly
It's kind of a mismatch: Three isolation levels but four things to worry about. Other database systems have one more isolation level: read uncommitted.
You can actually set the isolation level of a transaction to read uncommited, but internally there is no difference between read committed and read uncommited in Postgres.
Here is what the isolation levels in Postgres allow and what they prevent:
| Isolation Level | Dirty Read | Non repeatable Read | Phantom Read | Serialization Anomaly |
|---|---|---|---|---|
| Read uncommitted | 🚫 | ✅ | ✅ | ✅ |
| Read committed (default) | 🚫 | ✅ | ✅ | ✅ |
| Repeatable read | 🚫 | 🚫 | 🚫 | ✅ |
| Serializable | 🚫 | 🚫 | 🚫 | 🚫 |
As you can see, read uncommited does the exact same things as read commited so we'll ignore read uncommited from now on.
To understand what the different isolation levels do, we have to understand the four things to worry about in transactions.
Dirty Read
A dirty read is a read within a transaction that reads data from another, uncommitted transaction. Dirty reads are never allowed in Postgres transactions, regardless of the isolation level. If you try to create a dirty read within a transaction, this happens:
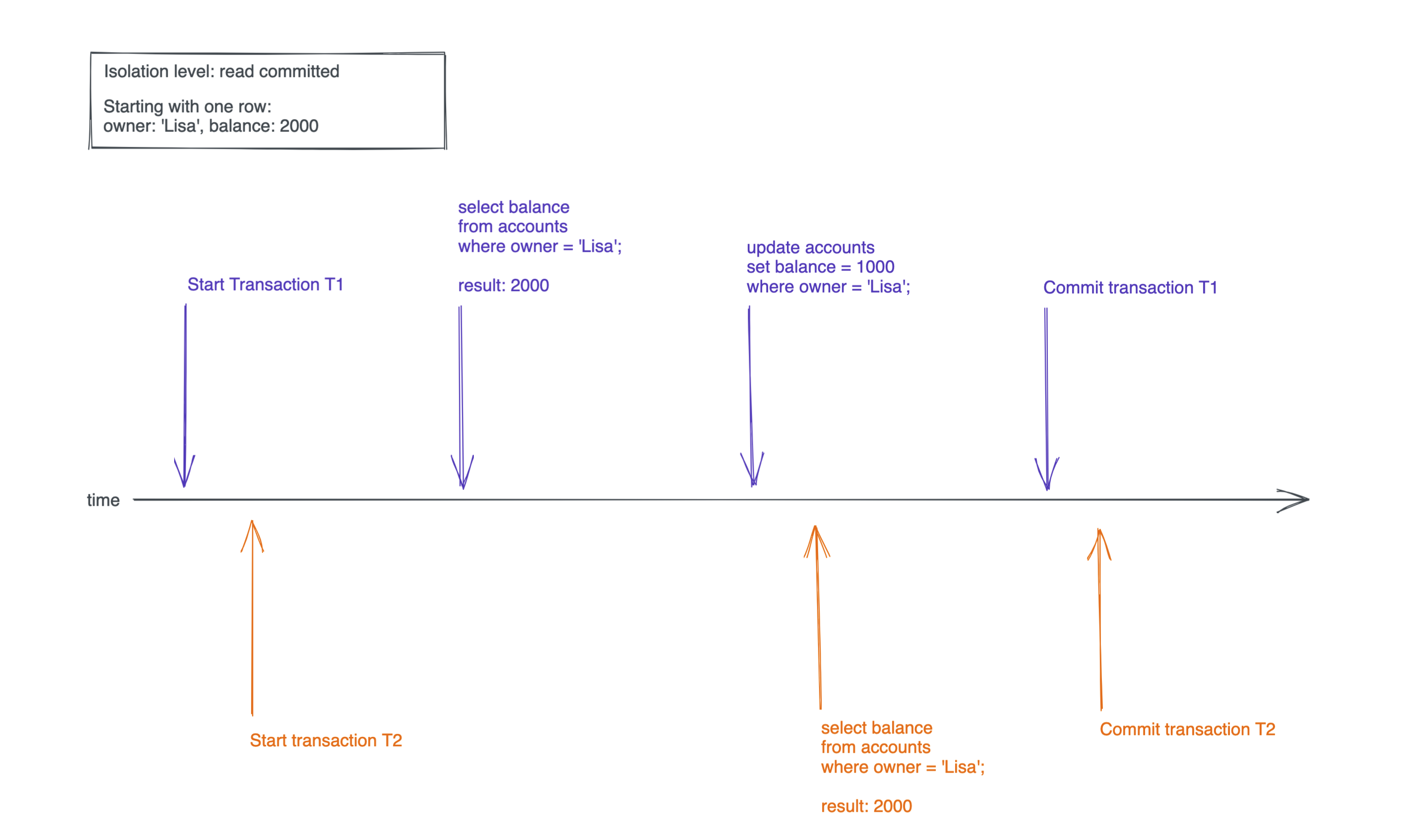
You would expect that the read in transaction T2 gets a balance of 1000, but that would be a dirty read, because transaction T1 didn't commit yet.
Non Repeatable Read
Non repeatable reads are the kind of phenomenon we tried to avoid in the example at the beginning of this article. We used the transaction level repeatable read to ensure that Lisa's balance is correct, even when purchases are happening concurrently.
In the example we had two concurrent transactions that looked like this:
-- begin transaction
begin transaction isolation level repeatable read;
-- check the balance to see if Lisa has enough coins
select balance from accounts where owner = 'Lisa';
-- update Lisa's balance
update accounts set balance = 1000 where owner = 'Lisa';
-- commit the transaction
commit;
When running two of these transactions concurrently with the isolation level repeatable read you'll get an error in transaction T2 once you commit T1. And when you then try to commit T2, T2 will perform a rollback:
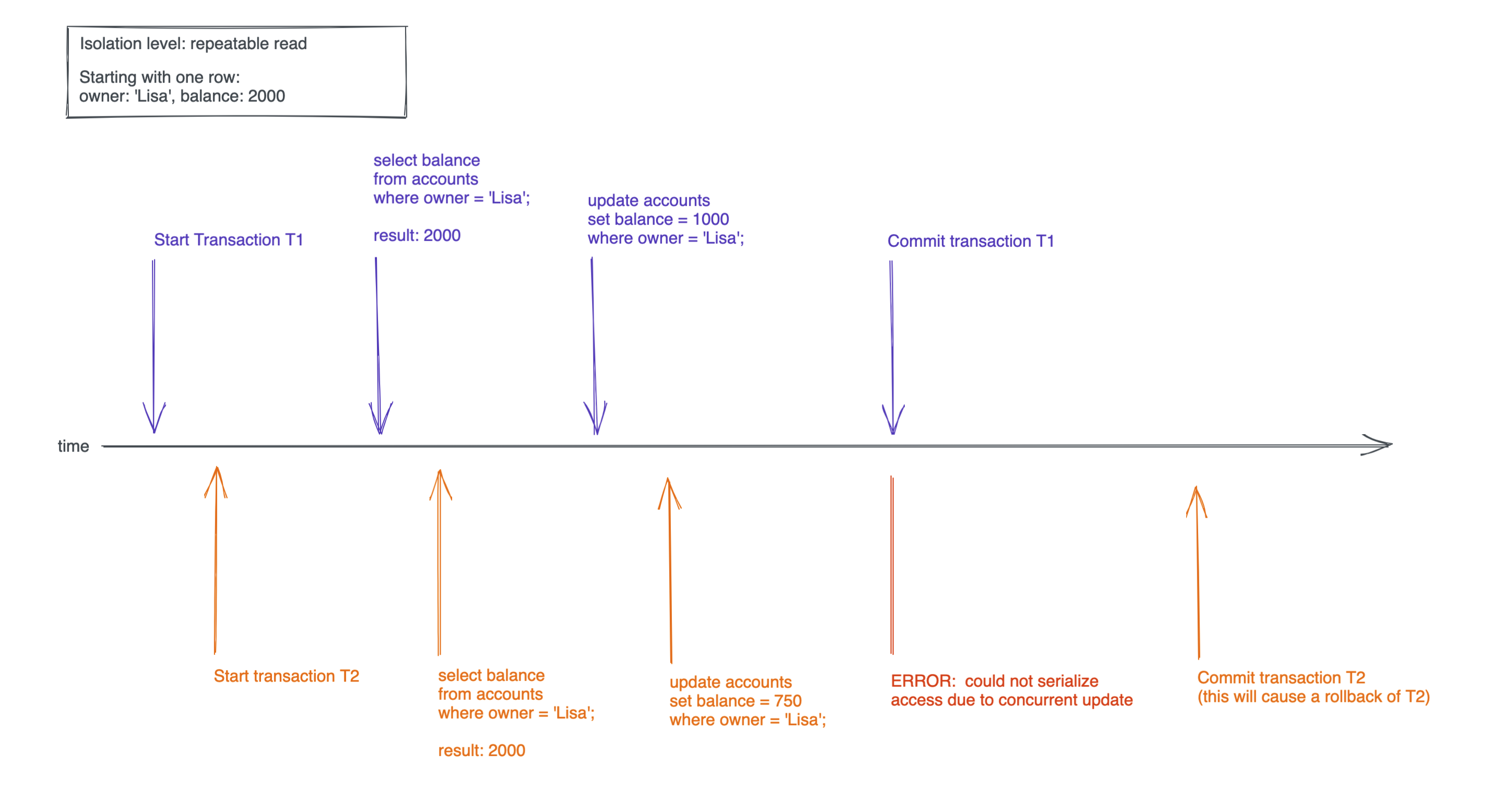
And even if you leave out the select statements...
-- begin transaction
begin transaction isolation level repeatable read;
-- update Lisa's balance
update accounts set balance = 500 where owner = 'Lisa';
-- commit the transaction
commit;
... you'll get the same error (could not serialize access due to concurrent update) when trying to run two of these transactions concurrently.
But without the select statements, are we still doing a non repeatable read? Yes! According to the Postgres docs:
UPDATE,DELETE,SELECT FOR UPDATE, andSELECT FOR SHAREcommands behave the same asSELECTin terms of searching for target rows [...]
Phantom Read
A phantom read occurs when transaction T1 reads some rows from a table, then another, concurrent transaction T2 adds rows that would be in the selection of T1 and commits, finally T1 performs the same select again, but gets more rows returned because of T2's insertion.
It's super complicated as a sentence, but much simpler in a picture:
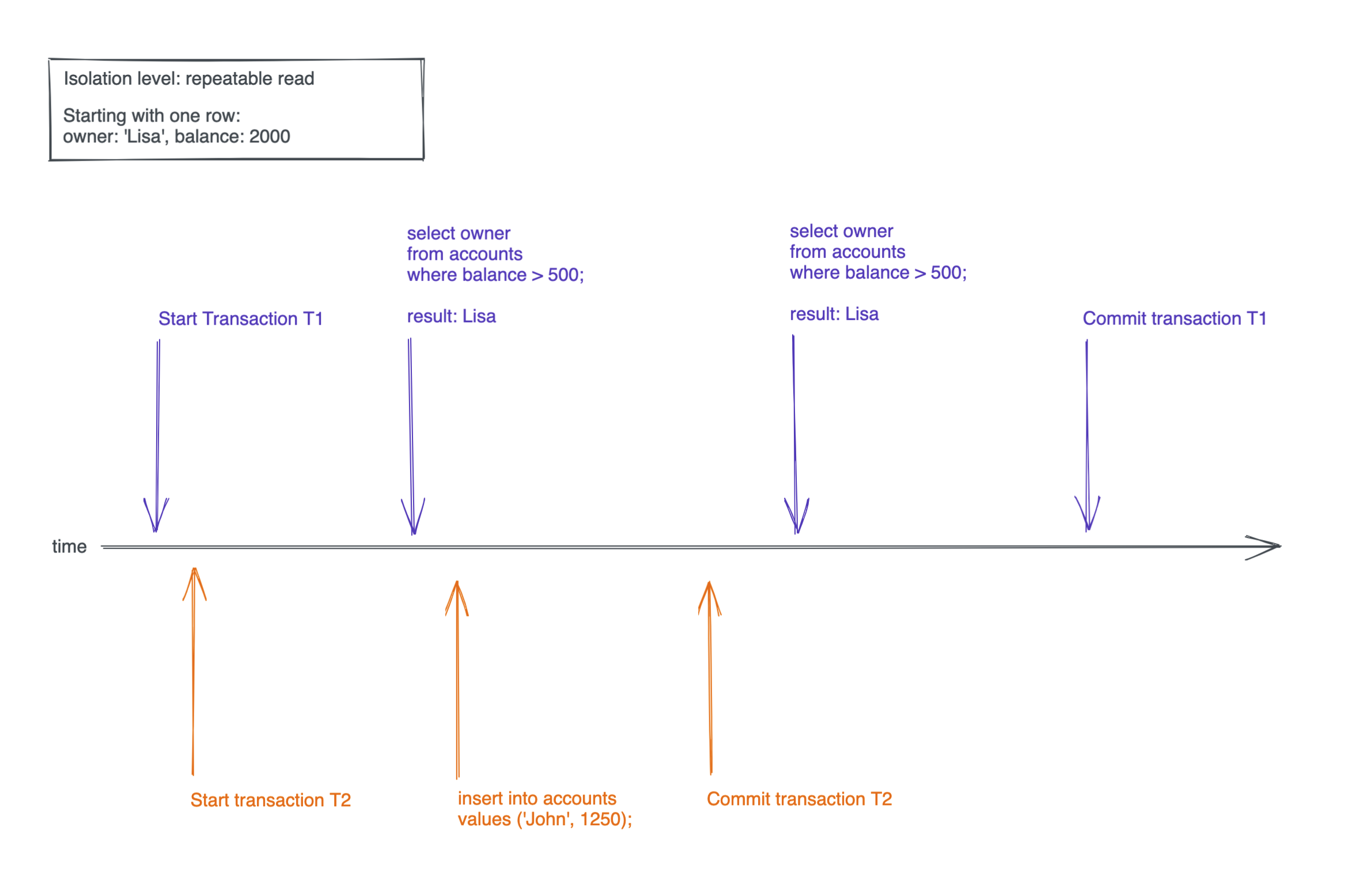
Let's try that in our terminal:
-- (re-) create the accounts table from the first example
create table if not exists accounts (owner text primary key, balance integer not null);
-- wipe the table
delete from accounts;
-- insert the first user
insert into accounts values ('Lisa', 2000);
From now on we're again working with two separate terminals (A & B) so that we can create concurrent transactions.
-- TERMINAL A
-- start transaction that prevents phantom reads
begin transaction isolation level repeatable read;
-- select rows from the accounts table
select * from accounts where balance > 500;
-- it returns:
owner | balance
-------+---------
Lisa | 2000
(1 row)
Now we switch to terminal B, start a transaction, insert a new row and commit:
-- TERMINAL B
-- start transaction
begin transaction isolation level repeatable read;
-- insert a new row
insert into accounts values ('John', 1250);
-- commit the transaction
commit;
Now back to terminal A and let's see what the same select statement returns:
-- TERMINAL A
-- select rows from the accounts table
select * from accounts where balance > 500;
-- it returns:
owner | balance
-------+---------
Lisa | 2000
(1 row)
Ha! We got just Lisa's row. If the select query also returned John's row, that would be a phantom read. But the isolation level we chose (repeatable read) does not allow that, so only Lisa's row is returned.
If you did the same steps with the lower isolation level read committed you would also get John's row, because read committed allows phantom reads:
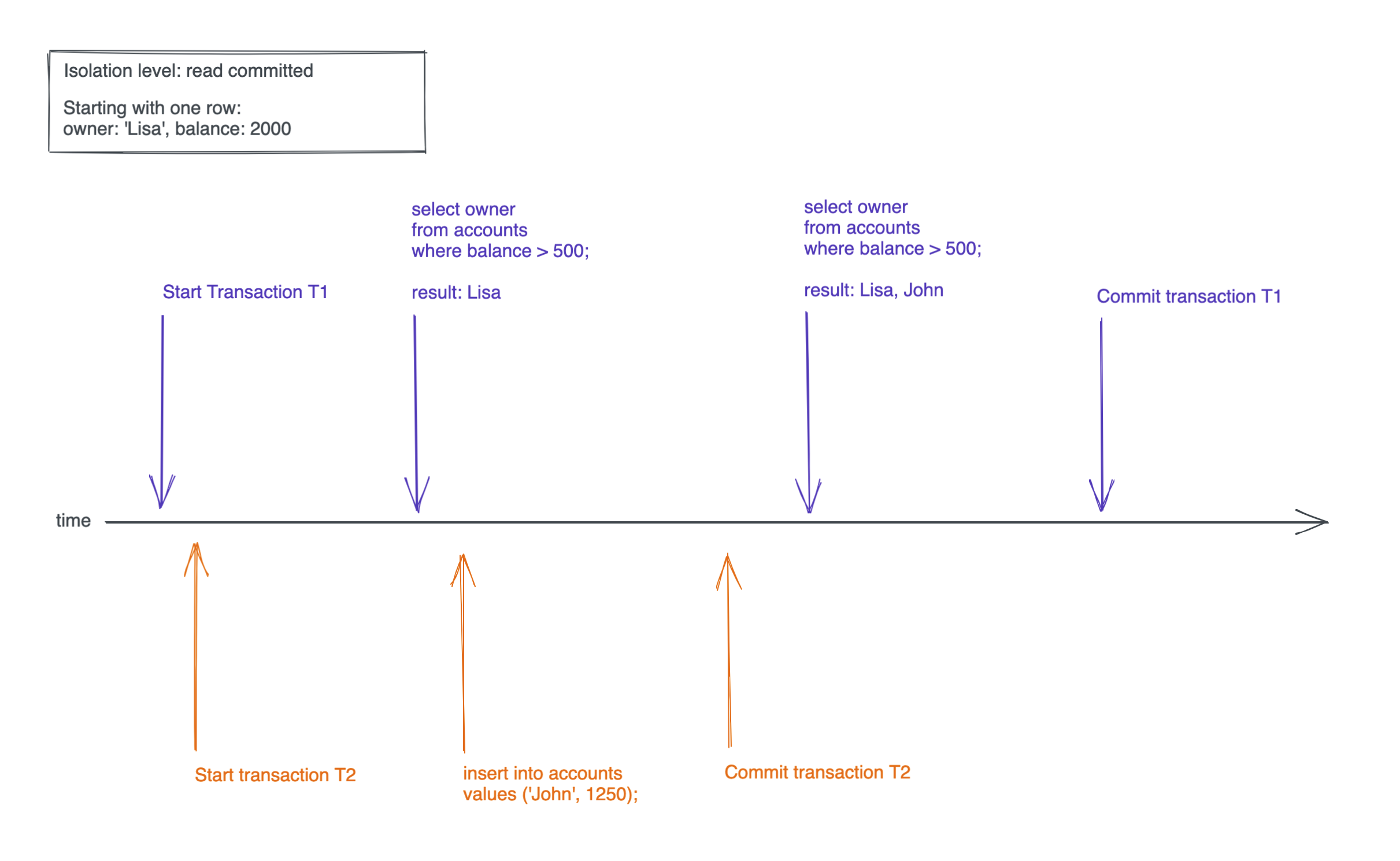
Serialization Anomaly
Serializable is the most restrictive isolation level in Postgres. When using this level, Postgres will prevent serialization anomaly. Meaning it ensures that concurrent transactions are only allowed if the result is the same, regardless of the order in which transactions are processed.
Let's use the accounts table one last time to see how that looks in sql. First we prepare our setup:
-- (re-) create the accounts table from the first example
create table if not exists accounts (owner text primary key, balance integer not null);
-- wipe the table
delete from accounts;
-- insert the first user
insert into accounts values ('Lisa', 2000);
Now we want to perform two transactions that produce different results, depending on the order of their execution. Both transactions will try to insert a new row into the table. The balance value will be equal to the sum of all balances in the table.
Again, we're working with two terminals (A & B) to be able to start two concurrent transactions:
-- TERMINAL A
-- start transaction
begin transaction isolation level serializable;
-- select rows from the accounts table
insert into accounts select 'transaction T1', sum(balance) from accounts;
-- TERMINAL B
-- start transaction
begin transaction isolation level serializable;
-- insert a new row
insert into accounts select 'transaction T2', sum(balance) from accounts;
Depending on which transaction is faster, we expect one of these results:
-- if T1 commits before T2
select * from accounts;
owner | balance
------------------+---------
Lisa | 2000
transaction T1 | 2000
transaction T2 | 4000
-- if T2 commits before T1
select * from accounts;
owner | balance
------------------+---------
Lisa | 2000
transaction T1 | 4000
transaction T2 | 2000
If T1 commits before T2, the sum for T1 should be 2000. By the time T2 commits, T2 should get 4000 as the sum of all balances (2000 for each Lisa and transaction T1).
But the transaction level serializable does not allow both transactions to commit. The first transaction that commits will be fine, but for the second one you commit you will get this:
ERROR: could not serialize access due to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
HINT: The transaction might succeed if retried.
Here is a timeline of the transactions:
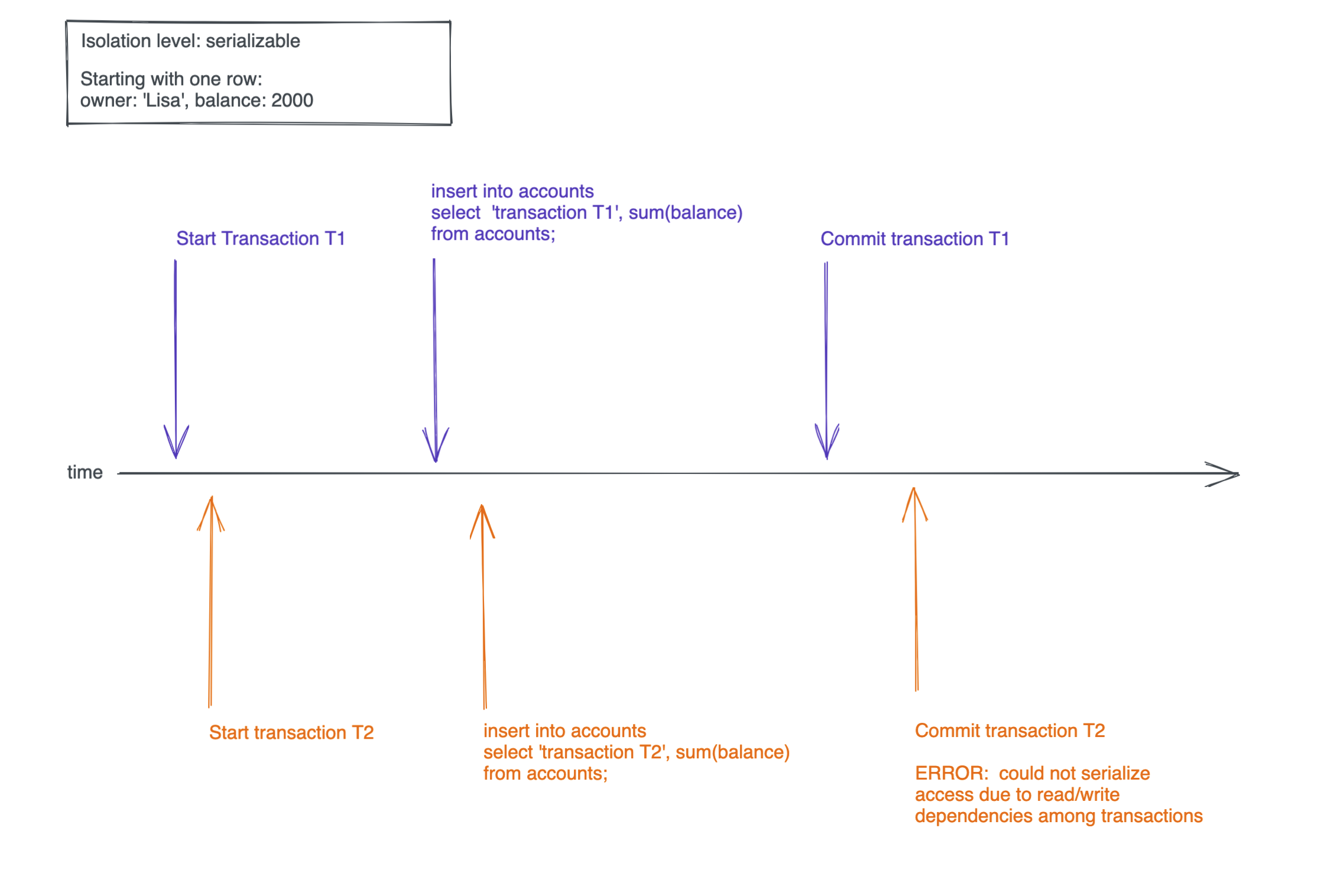
If you did the same transactions with one of the other two isolation levels, both transactions would be able to commit and the result would be:
select * from accounts;
owner | balance
----------------+---------
Lisa | 2000
transaction T1 | 2000
transaction T2 | 2000
And this is not what we expected. Either the balance of transaction T1 or transaction T1 should be 4000.
Because the order of execution matters for the outcome of these two transactions, the isolation level serializable will only allow one of them to commit.
Postgres again prevented us from ending up with the wrong balance.
We can now retry the failed transaction and given that no other interfering transaction is running, it will commit just fine 🚀
Conclusion
Transaction isolation is a powerful concept. It helps you to avoid inconsistent data without using a lot more business logic code.